









 您已经拒绝加入团体
您已经拒绝加入团体

 2026-02-03
2026-02-03
 1896
1896
 0
0
【摘要】 国家自然科学基金委员会于2026年1月23日通报20起科研不端案件,涉及46人,处理力度严厉,强调数据真实性和科研过程可追溯性已成为监管核心。文章指出风险前移至评审和申请阶段,并介绍源文件审核工具的重要性。

1月23日,国家自然科学基金委员会官网发布《案件通报(2026年1批)》,集中通报20起科研不端案件、涉案46人,处理力度空前严厉。其中,伪造篡改实验结果、图片造假成为高频违规问题,涉案人员均被取消基金申请资格、追回经费,部分面临长期科研限制。
这释放出明确信号:风险不再集中爆发在“论文发表后”,而是前移到了评审、申请、甚至数据准备阶段。
01数据真实,已是不可触碰的红线
从多起案件的处理逻辑可以清晰看出,监管关注的重点,已经从“结果是否成立”,转向“过程是否真实、可追溯”。无论是违规署名、冒名申请,还是数据买卖、实验结果伪造、图片拼接篡改,处理逻辑都指向同一个核心判断:科研活动的每一个关键节点,都是可被回溯与审查的。
尤其是在通报中反复出现的数据问题,本质并不只是“结果不对”,而是——源数据与实验过程无法被完整还原、解释与复现。
一旦被质疑,这类问题几乎无法通过“补充说明”自证,只能依赖原始数据、源文件和完整过程记录进行核查,结果往往直接触发撤项、追回经费,甚至长期科研资格限制。
02源文件,是科研成果的核心根基
在大量案例中,可以看到一个共同点:问题并非集中发生在“最后提交的那一步”,而是源于早期过程缺乏有效检查。比如:
● 数据在生成或整理阶段已存在异常,但未被识别
● 图片在反复修改、拼接过程中留下不可追溯的痕迹
● 源文件不完整,关键参数与步骤难以复现
这些问题在提交前往往难以被察觉,却在事后核查时成为无法回避的风险点。与此同时,监管逻辑也在变化:不只看“结果对不对”,更看“过程是否可追溯”,是否能清楚回答:数据从哪里来?怎么处理的?能不能复现?
在这种背景下,仅靠个人经验或人工自查,已经很难覆盖全部风险点。站在科研人员的角度,这带来了一个现实困境:不是你想造假,而是很多风险,单靠个人经验和人工自查,根本难以及时发现。
03源文件审核:把风险挡在“提交之前”
也正是在这样的现实需求下,科学指南针研发了【模拟计算AI源文件审核智能体】,一个在提交之前,帮助科研人提前发现源文件与计算过程风险的自查工具,它主要聚焦在以下4大高风险场景:
1. 任务并未真正完成,文件缺失
任务中途报错、提前终止、关键文件缺失,甚至根本没跑起来;
但这些“未完成”的任务,会被误当成“已完成结果”写进汇报或论文,暗藏巨大风险。
2. 数据造假:数据被拼接、挑选或篡改
将不同时间、不同体系、不同参数下得到的结果拼在一起,伪装成“连续、完整”的数据;
甚至通过删减、修改输入/输出文件,只保留“好看的部分”,真实计算过程从未完整发生。
3. 参数与精度不达标,结果偏离真实规律
刻意降低精度,或参数设置粗糙、不合理;
看似跑出了正常结果,实际上与实验或物理、化学反应严重偏离,却难以被察觉。
4. 过程不透明:无法复现、无法验证、无法追责
缺少完整源文件、版本记录和任务链路,输入输出不匹配、脚本混乱;
导致结果无法复现、逻辑无法验证,也缺乏足够证据证明数据是否可信。
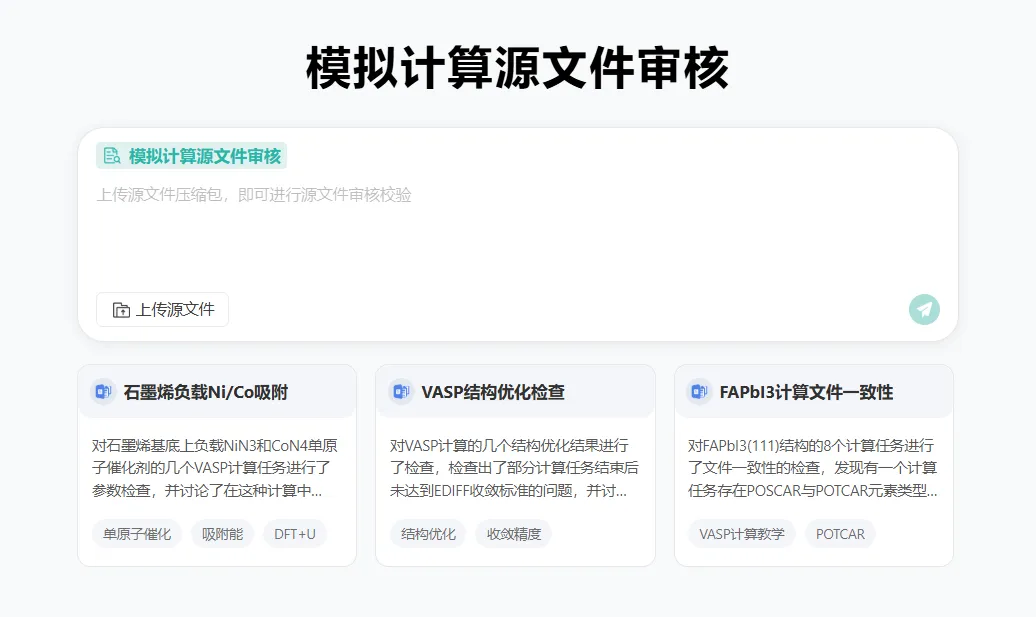
科研的核心是求真。科学指南针【模拟计算源文件AI审核智能体】,是为了帮助科研人守住诚信底线,让每一份研究成果都经得起检验,让科研人能更安心地专注于研究本身。








