









 您已经拒绝加入团体
您已经拒绝加入团体

 2021-07-14
2021-07-14
 8244
8244
 0
0
【摘要】 提到数据分析,首先会想到的可能是t检验、回归分析等各种具体的分析方法,但对于经历过完整数据分析的同学来说,最复杂、最耗费时间的步骤往往是数据的清理,也就是将数据整理成为能够进行上述统计分析的格式。因此,本节内容我们将对数据的准备进行简要介绍,重点介绍数据审核,其次会用少量篇幅简单介绍数据在进行分析时的适用性。
提到数据分析,首先会想到的可能是t检验、回归分析等各种具体的分析方法,但对于经历过完整数据分析的同学来说,最复杂、最耗费时间的步骤往往是数据的清理,也就是将数据整理成为能够进行上述统计分析的格式。因此,本节内容我们将对数据的准备进行简要介绍,重点介绍数据审核,其次会用少量篇幅简单介绍数据在进行分析时的适用性。
在数据审核方面,主要考虑的是数据的完整性和合理性,也就是对缺失数据和离群值进行识别和处理。
对缺失值的处理
在很多情况下,研究中所收集的数据会出现缺失情况,缺失的类型大致可以分为以下三种:
① 完全随机缺失(Missing completely at random,MCAR),数据缺失随机发生,与自身及其他变量均无关,任何变量的每一条记录发生缺失的概率相同。例如由于设备故障、样品运输丢失等导致的数据缺失,可视为MCAR[1]。这是最理想的情况,但在许多领域中这种情况并不合理;
② 随机缺失(Missing at random,MAR),是一种较为合理的情况。缺失值与自身变量无关,但与其他研究变量相关。假设老师的职称越高,提供其工资信息的可能性越低,那么每个职称分组中可认为老师工资信息缺失是随机发生的,可以通过加权的方法进行解决;
③ 非随机缺失(Missing not at random,MNAR),即缺失值与自身变量有关。例如一项研究中对受教育程度情况进行了调查,受教育程度较低的个体可能存在该变量的缺失,这就是非随机缺失。
对缺失值最好的处理方法是预防缺失的发生,即通过合理的研究设计、预试验的开展、调查员培训等方法尽量保证数据的完整性。但当缺失值不可避免时,就需要通过一些统计学方法对其进行处理:
① 缺失值删除
(a) 删除缺失数据行,适用于MCAR数据的处理,在大样本量且缺失较少的情况下很有效。该方法不会影响结果估计的准确性,但样本量会因此减小,从而影响结果的精确性;
(b) 删除缺失变量,适用于存在另一个无缺失的变量能够代替有缺失变量的情况,通常不建议采用这种方法,因为“保留数据总比删除数据好”;
(c) 选择性删除,在研究不同组合变量的相关关系时,可选择该组合内所有可用的数据进行估计,但由于模型不同部分的样本量可能不同,会导致研究结果的解释存在一定困难。
② 缺失值填补
(a) 均值、中位数和众数填补:根据数据分布,选择使用样本均值、中位数或众数对缺失值进行填补,没有考虑时序特征及变量间关系。该方法较为简单,但有明显缺陷,例如降低了数据方差;
(b) 多重填补:基于贝叶斯方法,创建多个填补数据集,即根据现有观测数据为每个缺失数据生成若干个可供填补的数值,结合填补后不同的结果,得出平均估计结果并考察缺失数据的不确定性[2];
(c) 回归填补:包括线性回归和Logistic回归。首先识别缺失变量的预测变量,其次使用无缺失记录生成预测方程,对缺失值进行预测:
(d) 虚拟变量设置:将是否缺失设置为虚拟变量,这是处理分类变量缺失较为简单的一种方法,但估计精度会下降;
(e) 线性内插法[3]:若缺失值与未缺失值间存在线性关系,根据缺失值的前一个和后一个观测值对缺失值进行计算;
(f) 临床试验中常用方法[4]:末次观察前推法(Last observation carried forward,LOCF),前次观察值后推法(Next observation carried backward,NOCB),基线值后推法(Baseline observation carried forward,BOCF),最差观测值推进法(Worst observation carried forward,WOCF)和将缺失值视为治疗失败法(Missing value treated as failure,MVTF)等。
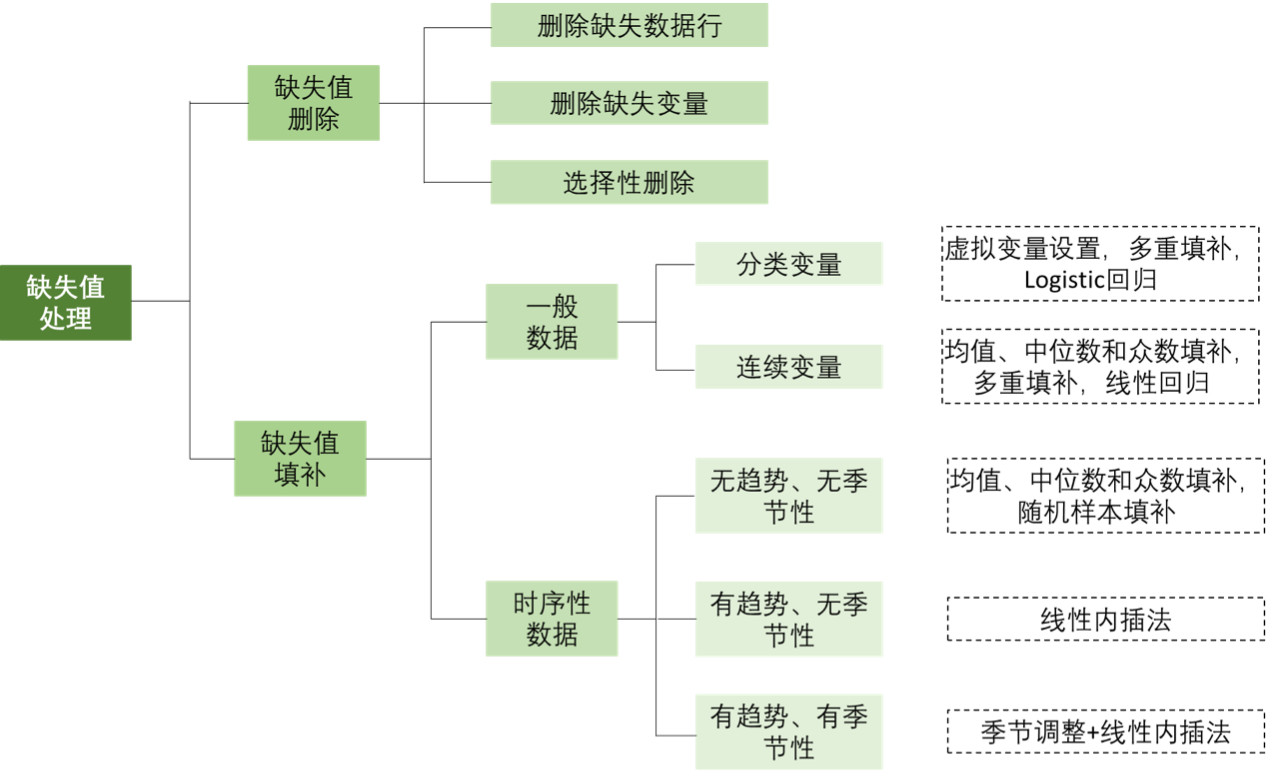
图1 缺失值处理方法的选择
(来源:https://towardsdatascience.com/how-to-handle-missing-data-8646b18db0d4)
对于完全随机缺失,简单的删除缺失数据行就可得到无偏的估计结果;对于随机缺失,一些复杂的统计方法可能会得到无偏估计结果;而对于非随机缺失,无法得到无偏估计结果,只能通过复杂的统计方法减小估计值的偏倚。
[1] Kang, H. (2013). The prevention and handling of the missing data. Korean journal of anesthesiology, 64(5), 402.
[2] Sterne, J. A., White, I. R., Carlin, J. B., Spratt, M., Royston, P., Kenward, M. G., ... & Carpenter, J. R. (2009). Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. BMJ, 338, b2393.
[3] Available at https://www.lexjansen.com/nesug/nesug01/ps/ps8026.pdf.
[4] Available at http://onbiostatistics.blogspot.com/2010/08/locf-bocf-wocf-and-mvtf.html.
以上仅为科学指南针检测平台对网上资料的收集整合,故此分享给大家,希望可以帮助大家对测试更了解,如有测试需求,可以和科学指南针联系,我们会给与您最准确的数据和最好的服务体验,惟祝科研工作者可以更轻松的工作。
免责声明:文章整合自网络,因内容庞杂无法联系到全部作者,如有侵权,请联系删除,我们会在第一时间予以答复,万分感谢。








