









 您已经拒绝加入团体
您已经拒绝加入团体

 2026-01-07
2026-01-07
 1459
1459
 0
0
【摘要】 本文解析EST研究:通过主动学习与分子动力学预测PFAS扩散系数,误差降低88%。科学指南针提供环境污染物迁移分析与检测服务。
全氟和多氟烷基物质(PFAS)作为环境持久性污染物,其迁移行为预测对风险评估至关重要。发表于《Environmental Science & Technology》(1区TOP,IF=10.8)的研究,通过融合主动学习、分子动力学与机器学习,构建了PFAS扩散系数预测框架,将预测误差降低88%,模型解释能力(R²)从0.095提升至0.907。本文解析该研究的创新方法与关键成果,科学指南针环境检测平台依托此类前沿技术,为PFAS迁移模拟与污染治理提供数据支持。
研究背景与创新点
PFAS包含超过14,000种化合物,传统实验测量扩散系数成本高、耗时长。该研究的核心创新在于:
-
主动学习框架:首次系统性应用不确定性引导的样本选择,优先对预测不确定性高的PFAS分子进行分子动力学模拟,迭代优化模型。
-
双特征编码:集成Mordred分子描述符和图论指纹,增强模型对多样化PFAS结构的泛化能力。
-
数据库构建:生成覆盖10,891种PFAS的扩散系数数据库,平均相对误差仅12.3%,为环境建模提供可靠基础。
关键结果解析
1.机器学习模型性能比较
随机森林算法在交叉验证中表现最优(R²=0.640),优于梯度提升、神经网络等模型,其均衡性能使其成为PFAS扩散预测的理想选择。
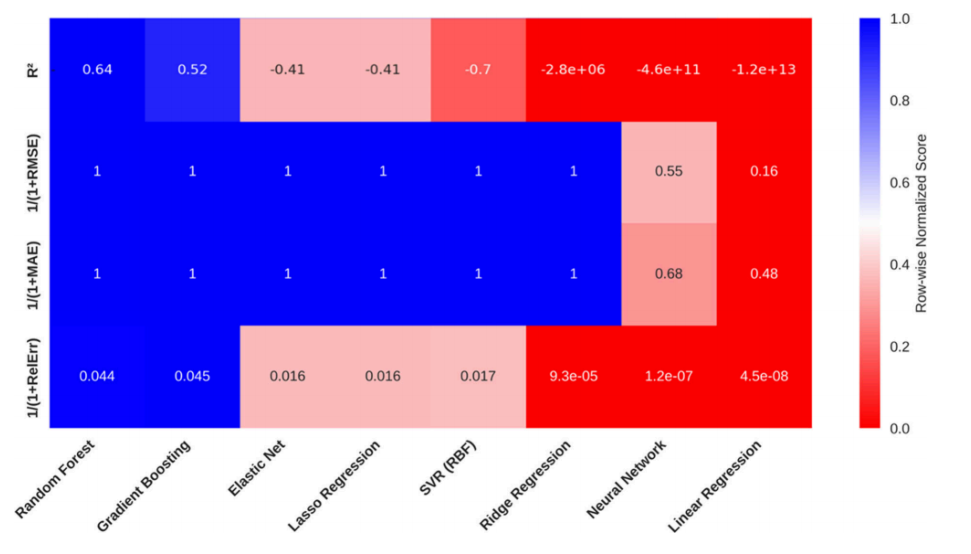
Figure 1:用于预测PFAS扩散系数的机器学习模型性能比较热力图。该热力图展示了不同算法在交叉验证统计下的性能指标,用于模型验证。训练与评估所用的数据集包含48种PFAS化合物。Y轴各行代表经过归一化处理的性能指标:R2分数、1/(1+RMSE)、1/(1+MAE) 以及 1/(1+RelErr)。其中,RMSE指均方根误差,MAE指平均绝对误差,RelErr指相对误差。所有误差指标均通过1/(1+error)公式进行转换,使其与R2的方向性保持一致,从而确保在所有指标中,数值越高均代表性能越好。颜色深度在每个指标内部进行了行归一化处理,以增强视觉对比效果,其中蓝色表示在该性能指标内相对更好的表现。
2.主动学习流程优化
框架通过迭代步骤(初始训练、不确定性选择、MD模拟、数据扩充)持续提升准确性。批量大小50-100时,基于不确定性的采样显著优于随机选择。
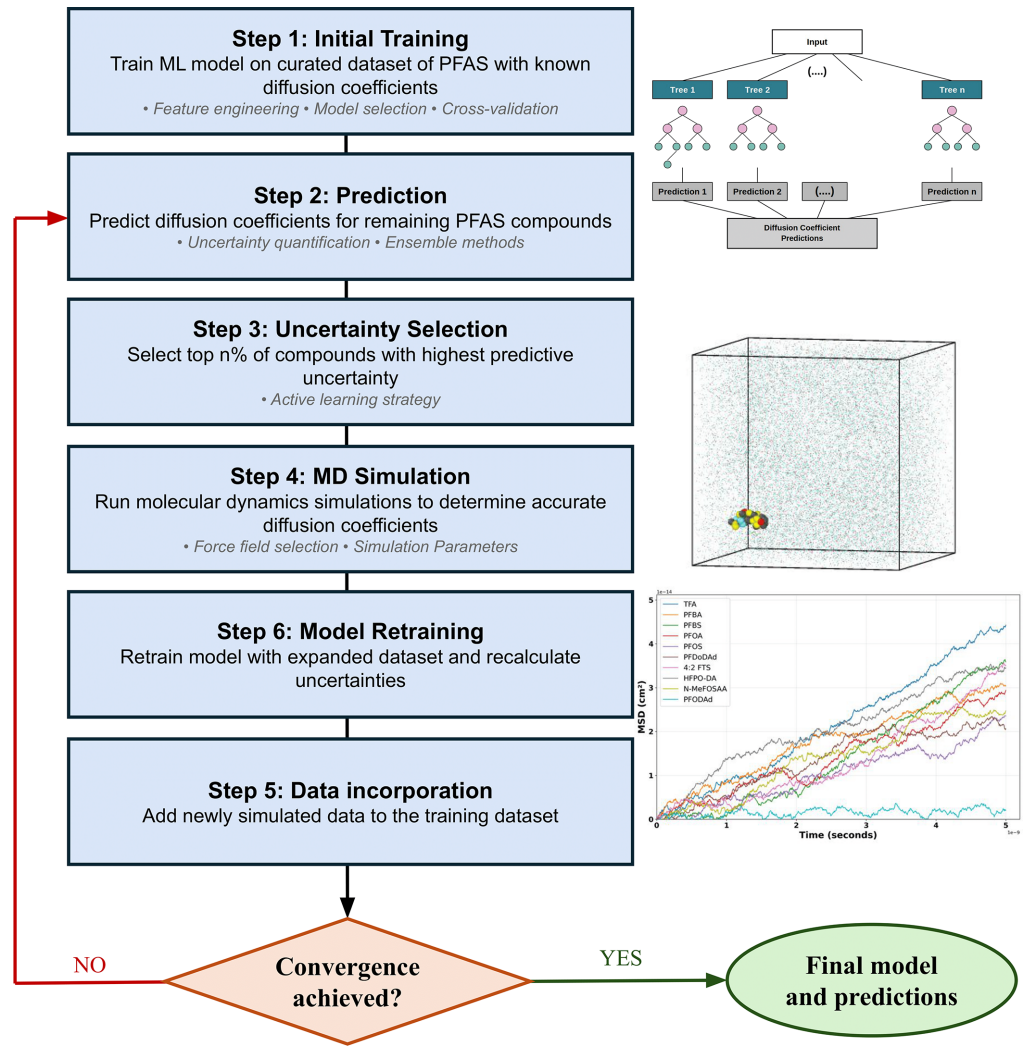
Figure 2:微主动学习框架流程图
3.分子动力学验证
模拟值与实验数据高度一致,均方位移曲线线性关系确认扩散行为正常,平均相对误差12.3%,验证了模拟可靠性。
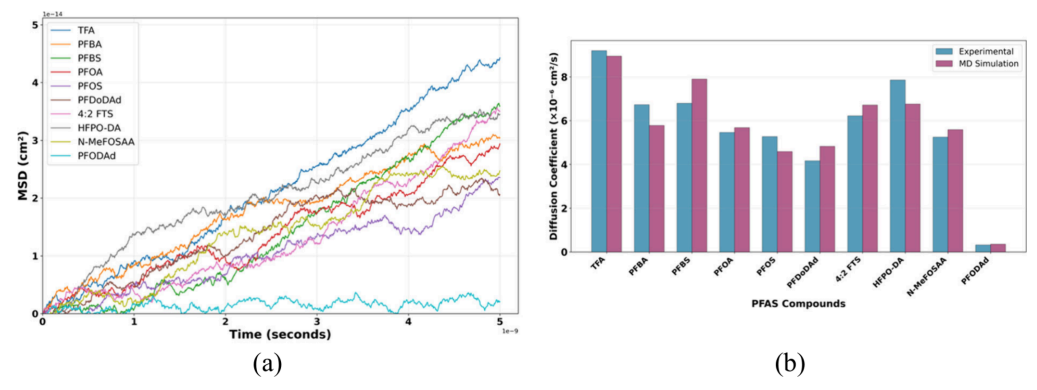
Figure 3:PFAS扩散系数的均方位移分析与分子动力学模拟验证。(a) 均方位移随时间的演变曲线。在扩散区呈现的线性关系证实了模拟系统已达到充分平衡,其斜率通过爱因斯坦关系式与扩散系数直接成正比。(b) 模拟与实验扩散系数之间相对误差的分布图,显示平均相对误差为12.3%,验证了PFAS分子动力学模拟的准确性。
4.模型收敛与不确定性分析
随着训练数据增加,模型误差降低,R²分数上升,预测不确定性系统性减小。不确定性与实际误差正相关,证实主动学习的有效性。
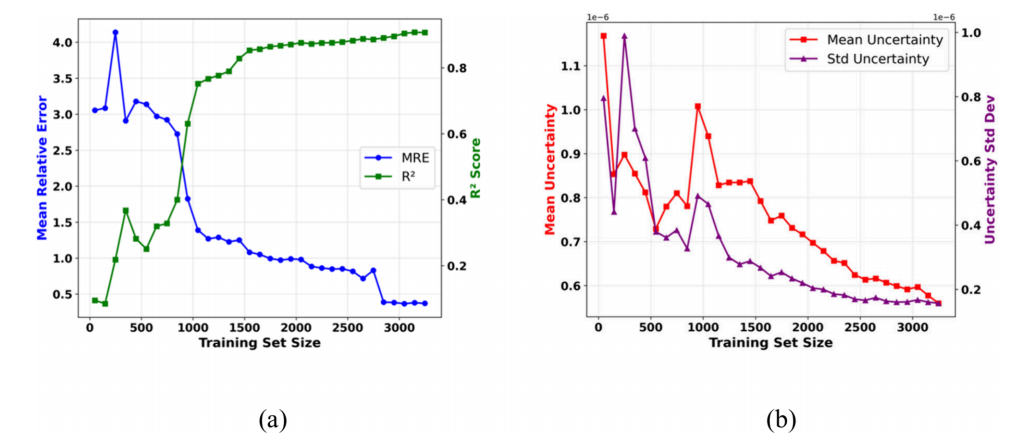
Figure 4:模型性能与不确定性指标在主动学习迭代中的演变。(a) 随训练集规模增加的MRE(蓝色)与R2分数(绿色)变化趋势综合视图。(b) 随训练数据量增加的不确定性均值(红色)与标准差(紫色)改善情况综合视图。
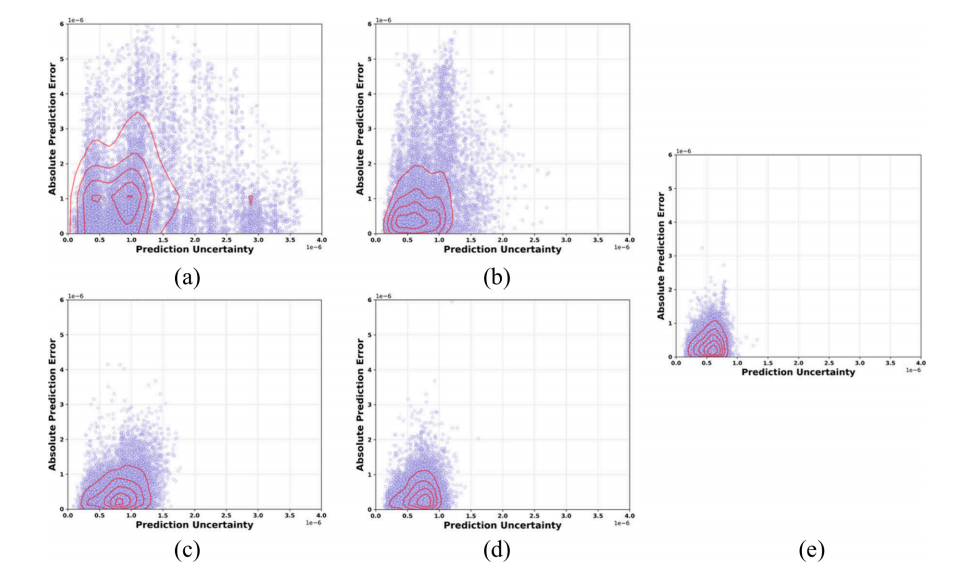
Figure 5:预测不确定性与误差相关性分析。(a)至(e)子图分别展示了第1、7、15、21和33次迭代的散点图,揭示了在验证样本上,模型预测不确定性与绝对预测误差之间的关系。
5.批量大小影响
批量50在数据效率上最优,批量100达到最高精度,批量150收敛快但精度低。策略性选择在中小批量下优势明显。
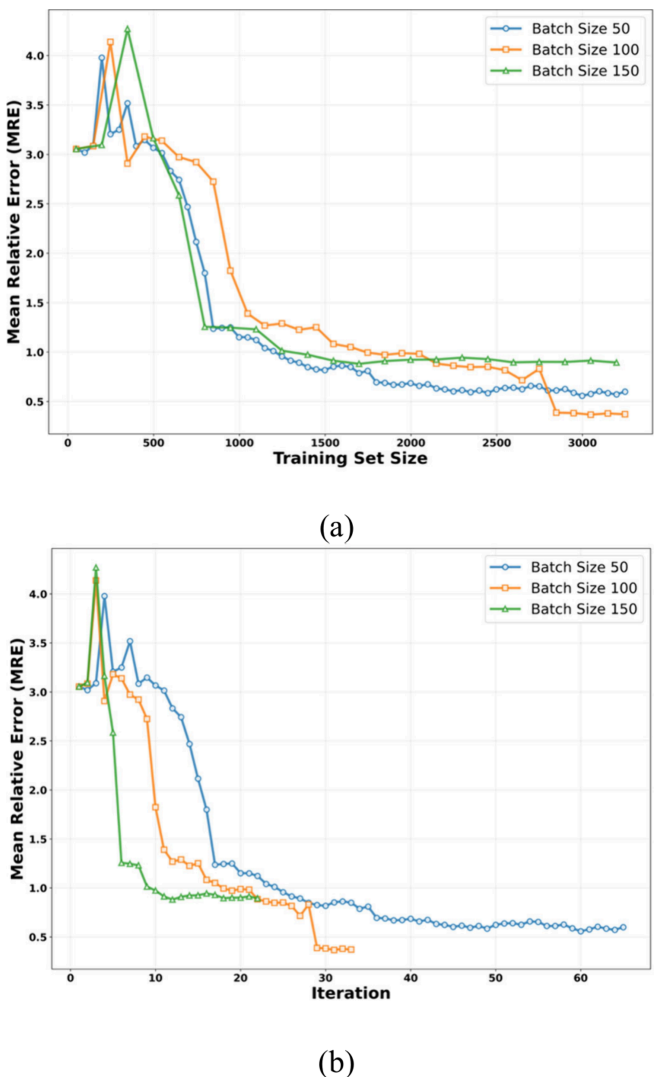
Figure 6:不同批量大小(50、100、150)在主动学习中的平均相对误差收敛对比。
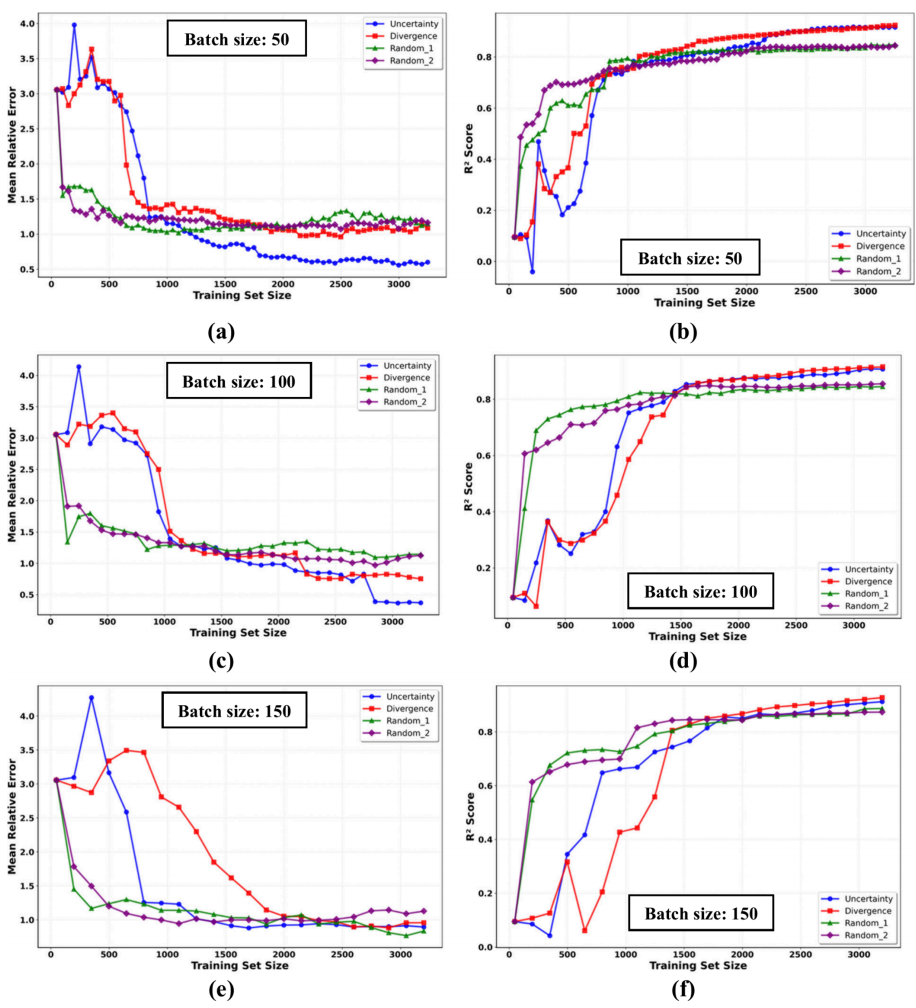
Figure 7:不同批量大小下主动学习策略的性能指标对比。 (a, b) 批量50, (c, d) 批量100, 以及 (e, f) 批量150。(a), (c), (e) 子图分别展示了批量大小为50、100、150时,平均相对误差随训练集规模的变化趋势;(b), (d), (f) 子图则分别展示了相应批量大小下,R2分数随训练集规模的变化趋势。。
研究结论与应用价值
该框架通过智能数据选择与多技术融合,解决了PFAS数据稀缺难题,为环境迁移建模和修复策略设计提供了高效工具。科学指南针环境检测平台整合机器学习与模拟技术,支持PFAS扩散行为分析、风险评估及定制化检测方案,助力污染物迁移预测与精准治理。








